

| Authors: | Danny E. P. Vanpoucke, Onno S. J. van Knippenberg, Ko Hermans, Katrien V. Bernaerts, and Siamak Mehrkanoon |
| Journal: | Journal of Applied Physics 128, 054901 (2020) |
| doi: | 10.1063/5.0012285 |
| IF(2019): | 2.286 |
| export: | bibtex |
| pdf: | <JApplPhys> (Open Access) |
| github: | <Amadeus> |
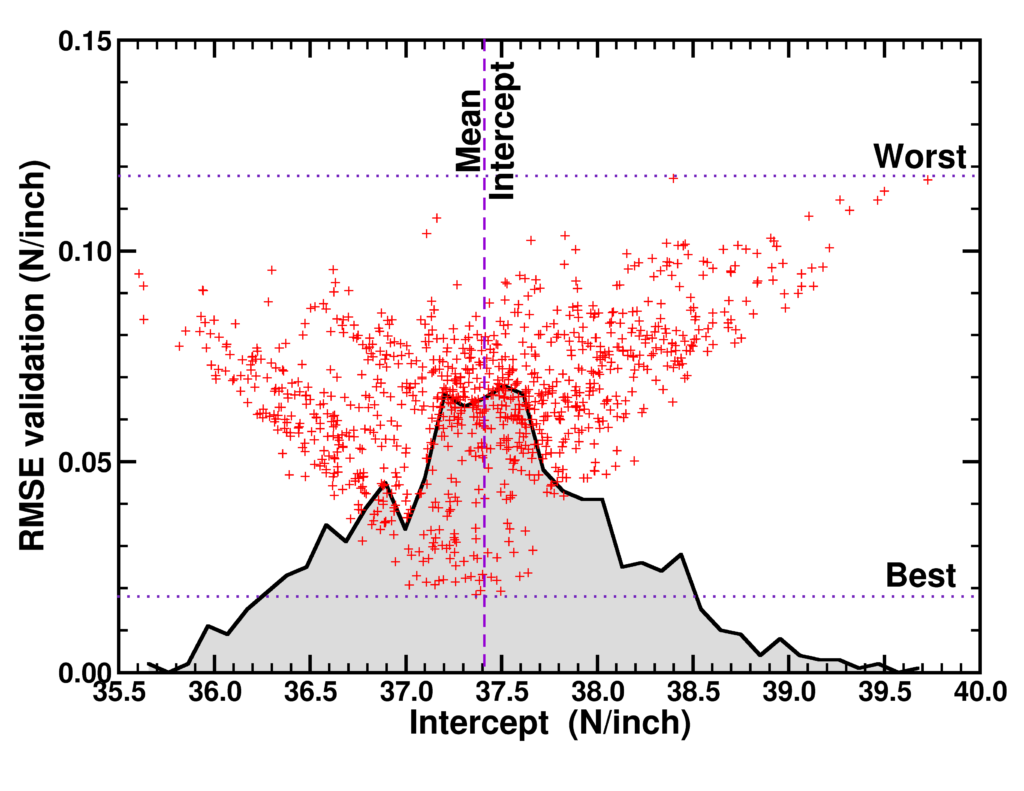 |
| Graphical Abstract: Correlation plot of the RMSE of the validation set and the intercept value for linear model instances trained on 1000 subsets of a 25 point data set. The distribution of the correlation data is indicated by the black curve. |
Abstract
Machine Learning is quickly becoming an important tool in modern materials design. Where many of its successes are rooted in huge data sets, the most common applications in academic and industrial materials design deal with data sets of at best a few tens of data points. Harnessing the power of Machine Learning in this context is therefore of considerable importance. In this work, we investigate the intricacies introduced by these small data sets. We show that individual data points introduce a significant chance factor in both model training and quality measurement. This chance factor can be mitigated by the introduction of an ensemble-averaged model. This model presents the highest accuracy while at the same time it is robust with regard to changing data set size. Furthermore, as only a single model instance needs to be stored and evaluated, it provides a highly efficient model for prediction purposes, ideally suited for the practical materials scientist.