

Individual model realizations may not perform that well, but the average model realization always performs very well.
Machine-Learning is up and trending. You can’t open a paper, magazine or website without someone trying to convince you their new AI-improved app/service will radically change your life. It will make the production of your company more efficient and cheaper, make costumers flock to your shop and possibly cure cancer on the side. Also in science, a lot of impressive claims are being made. General promises entail that it makes the research of interest faster, better, more efficient,… There is, however, a bit of fine print which is never explicitly mentioned: you need a LOT of data. This data is used to teach your Machine-Learning algorithm whatever it is intended to learn.
In some cases, you can get lucky, and this data is already available while in other, you still need to create it yourself. In case of computational materials science this often means performing millions upon millions of calculations to create a data set on which to train the Machine-Learning algorithm.[1] The resulting Machine-Learning model may be a thousand times faster in direct comparison, but only if you ignore the compute-time deficit you start from.
In materials science, this is not only a problem for those performing first principles modeling, but also for experimental researchers. When designing a new material, you generally do not have the resources to generate thousands or millions of samples while varying the parameters involved. Quite often you are happy if you can create even a few dozen samples. So, can this research still benefit from Machine-Learning if only very small data sets are available?
In my recent work on materials design using Machine-Learning combined with small data sets, I discuss the limitations of small data sets in the context of Machine-Learning and present a natural approach for obtaining the best possible model.[2] [3]
The Good, the Bad and the Average.
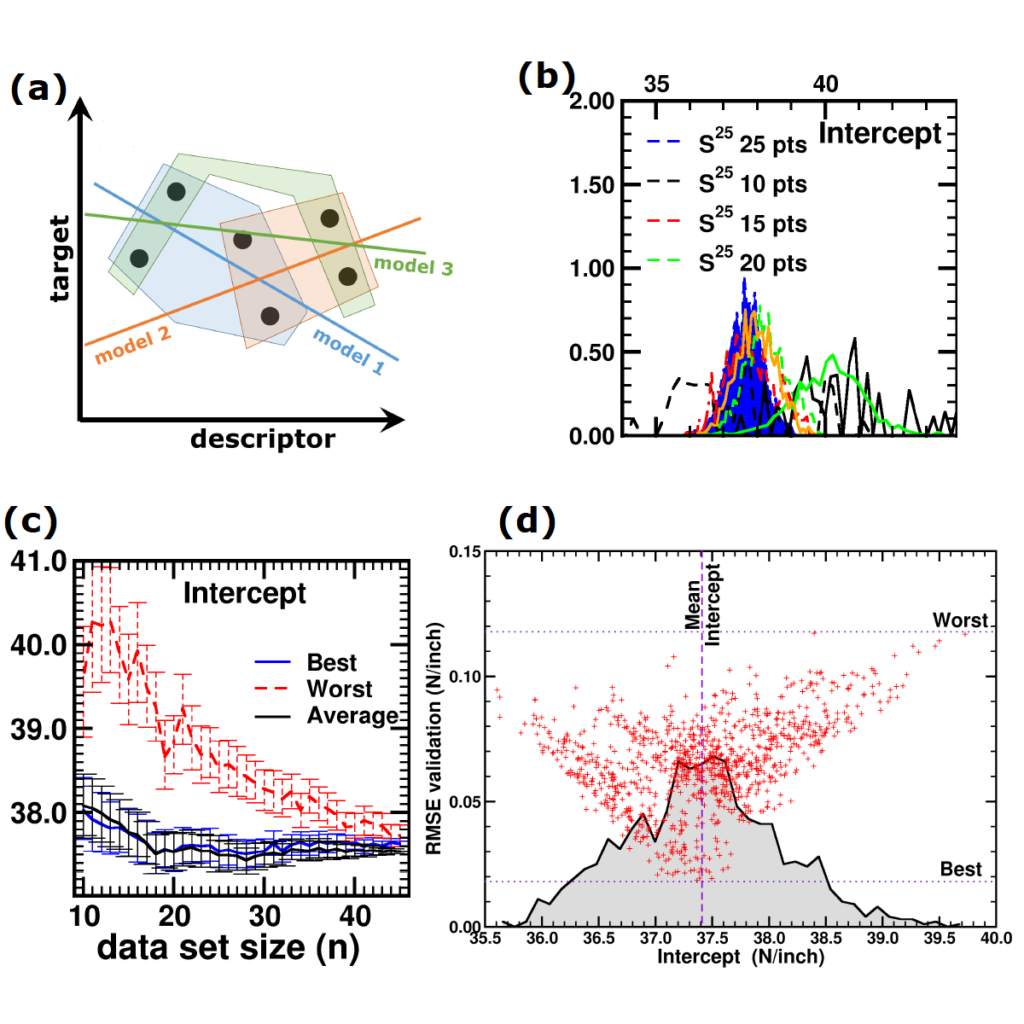
(a) Simplified representation of modeling small data sets. (b) Data set size dependence of the distribution of model coefficients. (c) Evolution of model-coefficients with data set size. (d) correlation between model coefficient value and model quality.
In Machine-Learning a data set is generally split in two parts. One part to train the model, and a second part to test the quality of the model. One of the underlying assumptions to this approach is that each subset of the data set provides an accurate representation of the “true” data/model. As a result, taking a different subset to train your data should give rise to “the same model” (ignoring small numerical fluctuations). Although this is generally true for large (and huge) data sets, for small data sets this is seldomly the case (cf. figure (a) on the side). There, the individual data points considered will have a significant impact on the final model, and different subsets give rise to very different models. Luckily the coefficients of these models still present a peaked distribution. (cf. figure (b)).
On the down side, however, if one isn’t careful in preprocessing the data set correctly, these distributions will not converge upon increasing the data set size, giving rise to erratic model behaviour.[2]
Not only the model coefficients give rise to a distribution, the same is true for the model quality. Using the same data set, but making a different split between training and test data can give rise to large differences in quality for the model instances. Interestingly, the model quality presents a strong correlation with the model coefficients, with the best quality model instances being closer to the “true” model instance. This gives rise to a simple approach: just take many train-test splittings, and select the best model. There are quite some problems with such an approach, which are discussed in the manuscript [2]. The most important one being the fact that the quality measure on a very small data set is very volatile itself. Another is the question of how many such splittings should be considered? Should it be an exhaustive search, or are any 10 random splits good enough (obviously not)? These problems are alleviated by the nice observation that “the average” model shows not the average quality or the average model coefficients, but instead it presents the quality of the best model (as well as the best model coefficients). (cf. figure (c) and (d))
This behaviour is caused by the fact that the best model instances have model coefficients which are also the average of the coefficient distributions. This observation hold for simple and complex model classes making it widely applicable. Furthermore, for model classes for which it is possible to define a single average model instance, it gives access to a very efficient predictive model as it only requires to store model coefficients for a single instance, and predictions only require a single evaluation. For models where this is not the case one can still make use of an ensemble average to benefit from the superior model quality, but at a higher computational cost.
References and footnotes
[1] For example, take “ANI-1: an extensible neural network potential with DFT accuracy at force field computational cost“, one of the most downloaded papers of the journal of Chemical Science. The data set the authors generated to train their neural network required them to optimize 58.000 molecules using DFT calculations. Furthermore, for these molecules a total of about 17.200.000 single-point energies were calculated (again at the DFT level). I leave it to the reader to estimate the amount of calculation time this requires.
[2] “Small Data Materials Design with Machine Learning: When the Average Model Knows Best“, Danny E. P. Vanpoucke, Onno S. J. van Knippenberg, Ko Hermans, Katrien V. Bernaerts, and Siamak Mehrkanoon, J. Appl. Phys. 128, 054901 (2020)
[3] “When the average model knows best“, Savannah Mandel, AIP SciLight 7 August (2020)