

Over the last weekend, two serious cyber security issues were hot news: Meltdown and Spectre [more links, and links](not to be mistaken for a title of a bond-movie). As a result, also academic HPC centers went into overdrive installing patches as fast as possible. The news of the two security issues went hand-in-hand with quite a few belittling comments toward the chip-designers ignoring the fact that no-one (including those complaining now) discovered the problem for over decade. Of course there was also the usual scare-mongering (cyber-criminals will hack our devices by next Monday, because hacks using these bugs are now immediately becoming their default tools etc.) typical since the beginning of the 21st century…but now it is time to return back to reality.
One of the big users on scientific HPC installations is the VASP program(an example), aimed at the quantum mechanical simulation of materials, and a program central to my own work. Due to an serendipitous coincidence of a annoyingly hard to converge job I had the opportunity to see the impact of the Meltdown and Spectre patches on the performance of VASP: 16% performance loss (within the range of the expected 10-50% performance loss for high performance applications [1][2][3]).
The case:
- large HSE06 calculation of a 71 atom defective ZnO supercell.
- 14 irreducible k-points (no reduction of the Hartree-Fock k-points)
- 14 nodes of 24 cores, with KPAR=14, and NPAR=1 (I know NPAR=24 is the recommended option)
The calculation took several runs of about 10 electronic steps (of each about 5-6 h wall-time, about 2.54 years of CPU-time per run) . The relative average time is shown below (error-bars are the standard deviation of the times within a single run). As the final step takes about 50% longer it is treated separately. As you can see, the variation in time between different electronic steps is rather small (even running on a different cluster only changes the time by a few %). The impact of the Meltdown/Spectre patch gives a significant impact.
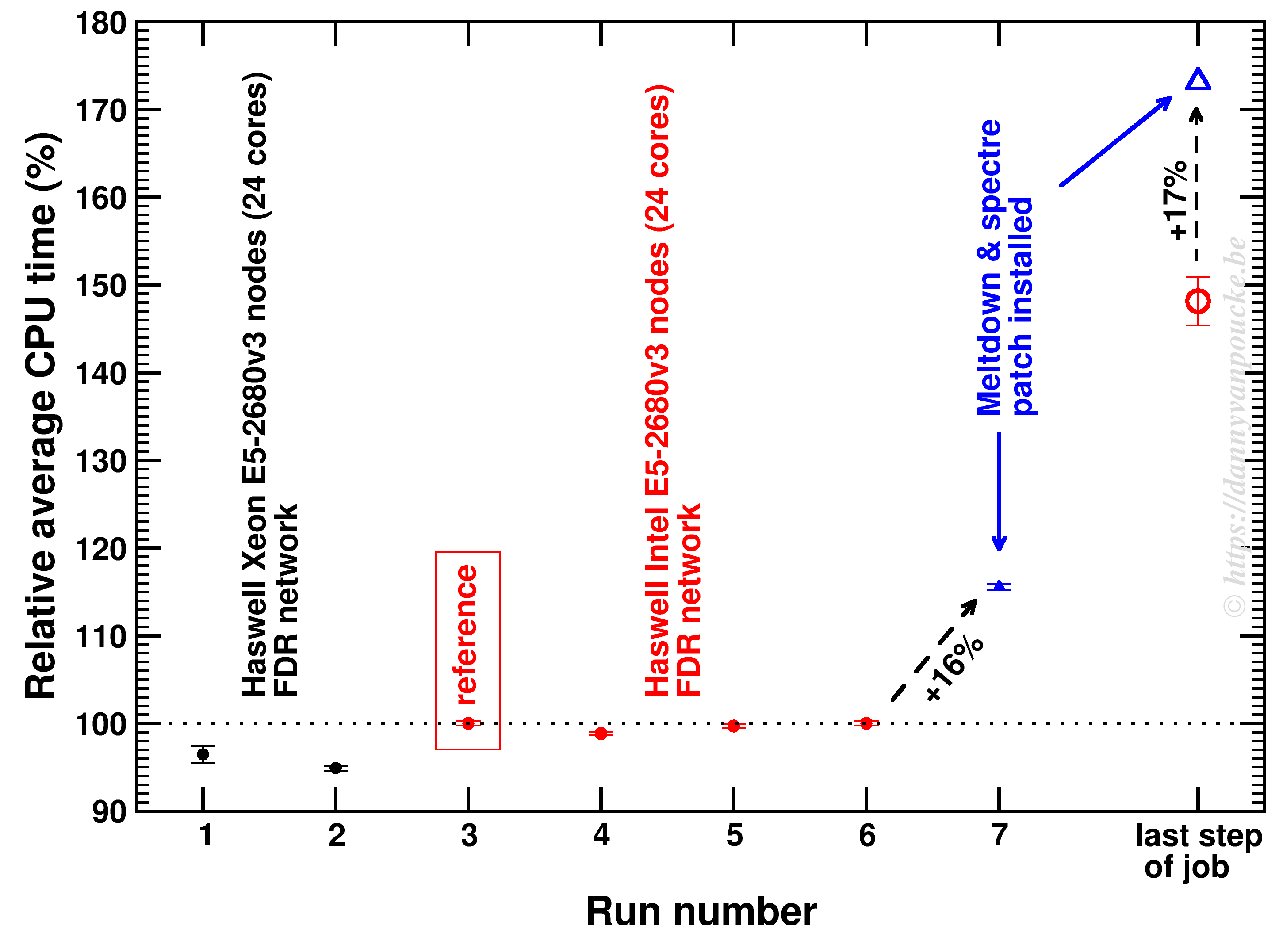
Impact of Meltdown/Spectre patch on VASP performance for a 336 core MPI job.
The HPC team is currently looking into possible workarounds that could (partially) alleviate the problem. VASP itself is rather little I/O intensive, and a first check by the HPC team points toward MPI (the parallelisation framework required for multi-node jobs) being ‘a’ if not ‘the’ culprit. This means that also an impact on other multi-node programs is to be expected. On the bright side, finding a workaround for MPI would be beneficial for all of them as well.
So far, tests I performed with the HPC team not shown any improvements (recompiling VASP didn’t help, nor an MPI related fix). Let’s keep our fingers crossed, and hope the future brings insight and a solution.