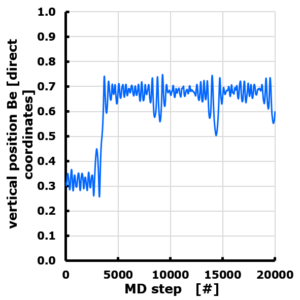
After a relatively chill week six, the seventh week of the academic year ended up being complicated. As it was fall-break the week only consisted of two class days at university. However, primary schools are closed entirely so our son was at home having a holiday, while both parents were trying to juggle classes and project proposal deadlines as well as additional administrative reporting. A second evaluation meeting with the students of our materiomics program at UHasselt took place (second master this time), and also these students appreciated the effort put into creating their classes.
Although there were only two days of teaching, this did not mean there was little work there. The students of the second bachelor in chemistry extended their knowledge of a particle in a box to the model of a particle on a ring, during the course introduction to quantum chemistry. Similar as for a particle in a box, this can be considered a simplified model for a circular molecule like benzene, allowing us to estimate the first excitation quite accurately.
For the course Fundamentals of Materials Modeling, there was a lecture introducing the first master students materiomics into the very basics of machine learning, as well as an exercise session. During these, the students learned about linear regression, decision trees and support vector machines. This class was also open to students of the bachelor programs to get a bit of an idea of the content of the materiomics program. Finally, the first master students also presented the results of their lab on finite element modeling as part of the course Fundamentals of Materials Modeling. They presented flow studies around arrows, reef and car models, as well as heat transfer in complex partially insulated systems, as well as sinking boats. They showed they clearly gained insight through this type of hands-on tasks, which is always a joy to note, resulting in grades reflecting their efforts and insights.
Though this week was rather short, we added another 6h of classes, putting our semester total at 91h of live lectures. Upwards and onward to week 8.