

Computational as a third pillar of science (next to experimental and theoretical) is steadily developing in many fields of science. Even some fields you would less expect it, such as sociology or psychology. In other fields such as physics, chemistry or biology it is much more widespread, with people pushing the boundaries of what is possible. Larger facilities provide access to larger problems to tackle. If a computational physicist is asked if larger infrastructures would not become too big, he’ll just shrug and reply: “Don’t worry, we will easily fill it up, even a machine 1000x larger than that.” An example is given by a pair of physicists who recently published their atomic scale study of the HIV-1 virus. Their simulation of a model containing more than 64 million atoms used force fields, making the simulation orders of magnitude cheaper than quantum mechanical calculations. Despite this enormous speedup, their simulation of 1.2 µs out of the life of an HIV-1 virus (actually it was only the outer skin of the virus, the inside was left empty) still took about 150 days on 3880 nodes of 16 cores on the Titan super computer of Oak Ridge National Laboratory (think about 25 512 years on your own computer).
In Flanders, scientist can make use of the TIER-1 facilities provided by the Flemish Super Computer (VSC). The first Tier-1 machine was installed and hosted at Ghent University. At the end of it’s life cycle the new Tier-1 machine (Breniac) was installed and is hosted at KULeuven. Although our Tier-1 supercomputer is rather modest compared to the Oak Ridge supercomputer (The HIV-1 calculation I mentioned earlier would require 1.5 years of full time calculations on the entire machine!) it allows Flemish scientists (including myself) to do things which are not possible on personal desktops or local clusters. I have been lucky, as all my applications for calculation time were successful (granting me between 1.5 and 2.5 million hours of CPU time every year). With the installment of the new supercomputer accounting of the requested resources has become fully integrated and automated. Several commands are available which provide accounting information, of which mam-balance is the most important one, as it tells how much credits are still available. However, if you are running many calculations you may want to know how many resources you are actually asking and using in real-time. For this reason, I wrote a small bash-script that collects the number of requested and used resources for running jobs:



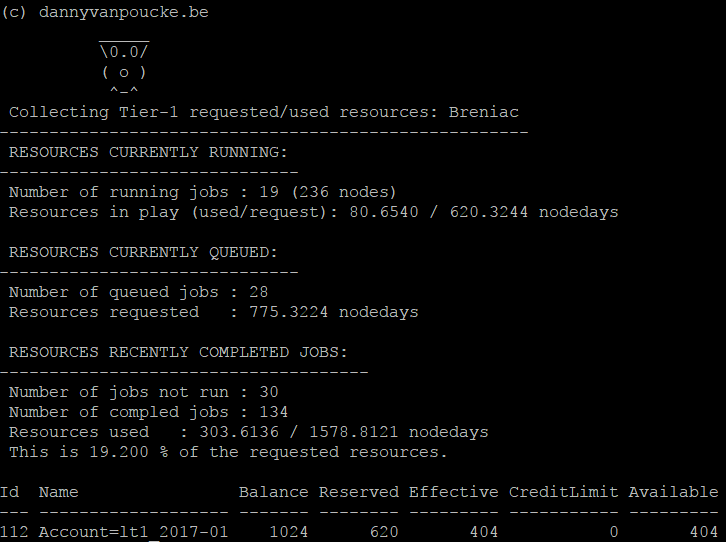
Output of the Bash Script.
Currently, the last part, on the completed jobs, only provides data based on the most recent jobs. Apparently the full qstat information of older jobs is erased. However, it still provides an educated guess of what you will be using for the still queued jobs.