Most commented posts
- Start to Fortran — 1 comment
- Phonons: shake those atoms — 3 comments


Jul 18 2022
In the previous tutorial of the wordle-mania-series, we had a quick overview of how to construct a basic class in Python. Here we take our class adventure a step further and implement a child class. As before, the full source of this project can be found in our GitHub repo.
The construction of a child class is near identical to the construction of a non-child class. The only difference being we need to somehow indicate the class is derived from another class. During our previous tutorial, we created the WordleAssistant class, so let’s use it as a parent for the WordleAssistant2 child class.
from .WordleAssistant import WordleAssistant class WordleAssistant2(WordleAssistant): pass
First, note that we need to import the WordleAssistant class, which is stored in a file WordleAssistant.py, contained in the same folder as the file containing our child class (hence the “.” in front of WordleAssistant). At this point, most python developers will hate me for using the same name for what is considered a module and a class, as you could put multiple classes in a single file. Then again, once you start writing object oriented code, it is good practice to put only one class in a single file, which makes it rather strange to use different names.
Second, we put parent class between the brackets of the child class. Through this simple action, and the magic of inheritance, we just created an entirely new class containing all functions and functionality of the parent class. The keyword pass is used to indicate no further methods and attributes will be added.
Of course, we want our child class to not be just a wrapper of the parent class. The choice to use a child class can be twofold:
In our case, we are going to ‘upgrade‘ our WordleAssistant class by considering the prevalence of every letter at the specific position in the 5-letter word. This in contrast to our original implementation which only considered the prevalence of a letter anywhere in the word. Adding new functionality with “new” methods and attributes, happens as for the parent class. You just define the new methods and attributes, which should have names that differ from the names for methods and attributes already used by the parent class.
However, sometimes, you may want or have to modify existing methods. You can either replace the entire functionality overwriting that of the parent method, or you may extend that functionality.
When you still want to make use of the functionality of the method of the parent class you could just copy that code, and add your own code to extend it. This however makes your code hard to maintain, as each time the parent class code is modified, you would need to modify your child class as well. This increases the risk of breaking the code. Luckily, similar as programming languages like C++ and Object Pascal, there is a useful trick which allows you to wrap the parent class code in your overwritten child class method. A location where this trick is most often used is the initialization method. Below you can see the __init__ function of the WordleAssistant2 child class.
def __init__(self, size: int = 5, dictionary : str = None ): super().__init__(size, dictionary) self.FullLettPrevSite = self._letterDistSite(self.FullWorddict) self.CurLettPrevSite = copy.deepcopy(self.FullLettPrevSite)
The super() function indicates we are going to access the methods of the parent of the class we are working in at the moment. The super().__init__() method therefor refers to the __init__ method of the WordleAssistant class. This means the __init__ method of the WordleAssistant2 child class will first perform the __init__ method of the WordleAssistant class and then execute the following two statements which initialize our new attributes. Pretty simple, and very efficient.
In some cases, you don’t want to retain anything of the parent method. By overwriting a method, your child class will now use a totally new code which does not retain any functionality of the parent method. Note that in the previous section we were also overwriting the __init__ method, but we retained some functionality via the call using super(). An example case of a full overwrite is found in the _calcScore method:
def _calcScore(self, WD: dict, LP: list): for key in WD: WD[key]['score'] = 0 for i in range(self.WordleSize): WD[key]['score'] += self.CurLettPrevSite[i][WD[key]['letters'][i]]
Although this method can still make use of attributes (self.WordleSize) and methods of the parent class, the implementation is very different and unrelated to that of the parent class. This is especially true in case of the python scripting language. Where a programming language like C++ or Object Pascal will require you to return the same type of result (e.g. the parent class returns an integer, then the child class can not return a string, or even a float.), python does not care. It places the burden of checking this downstream: i.e. with the user. As a developer, it is therefore good practice to be better than standard python and take away as much of this burden from the future users of your code (which could be your future self.)
Finally, a small word of caution with regard to name mangling. Methods with two leading underscores can not be overwritten in the child class in the sense that these methods are not accessible outside the parent class. This means also inside a child class these methods are out of scope. If we had a __calcScore method instead, creating an additional __calcScore in our child class would give rise to a lot of confusion (for python and yourself) and unexpected behavior.
Permanent link to this article: https://dannyvanpoucke.be/python-tutorial-child-classes/
Jul 18 2022
| Authors: | Danny E.P. Vanpoucke, Marie A.F. Delgove, Jules Stouten, Jurrie Noordijk, Nils De Vos, Kamiel Matthysen, Geert G.P. Deroover, Siamak Mehrkanoon, and Katrien V. Bernaerts |
| Journal: | Polymer International 71(8), i-i (2022) |
| doi: | 10.1002/pi.6434 |
| IF(2015): | 3.213 |
| export: | bibtex |
| pdf: | <PolymerInt> |
The cover image is based on the Research Article A machine learning approach for the design of hyperbranched polymeric dispersing agents based on aliphatic polyesters for radiation-curable inks by Danny E.P. Vanpoucke et al., https://doi.org/10.1002/pi.6378. (The related paper can be found here.)

Cover Polymer International: Machine learning on small data sets, application on UV curable inks.
Permanent link to this article: https://dannyvanpoucke.be/paper2022_mldannycover-en/
Jul 16 2022
| Authors: | Danny E.P. Vanpoucke, Marie A.F. Delgove, Jules Stouten, Jurrie Noordijk, Nils De Vos, Kamiel Matthysen, Geert G.P. Deroover, Siamak Mehrkanoon, and Katrien V. Bernaerts |
| Journal: | Polymer International 71(8), 966-975 (2022) |
| doi: | 10.1002/pi.6378 |
| IF(2021): | 3.213 |
| export: | bibtex |
| pdf: | <PI> (Open Access) (Cover Paper) |
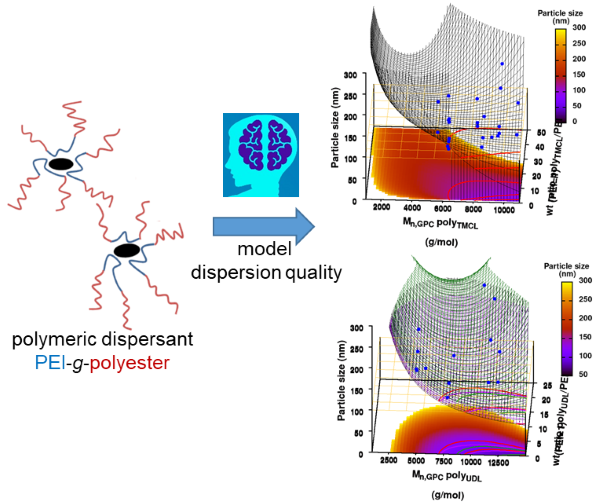 |
| Graphical Abstract:An ensemble based machine learning model for small datasets was used to predict the relationship between the dispersant structure and the pigment dispersion quality (particle size) for radiation curable formulations. |
Polymeric dispersing agents were prepared from aliphatic polyesters consisting of δ-undecalactone (UDL) and β,δ-trimethyl-ε-caprolactones (TMCL) as biobased monomers, which are polymerized in bulk via organocatalysts. Graft copolymers were obtained by coupling of the polyesters to poly(ethylene imine) (PEI) in the bulk without using solvents. Different parameters that influence the performance of the dispersing agents in pigment based UV-curable matrices were investigated: chemistry of the polyester (UDL or TMCL), weight ratio of polyester/PEI, molecular weight of the polyesters and of PEI. The performance of the dispersing agents was modelled using machine learning in order to increase the efficiency of the dispersant design. The resulting models were presented as analytical models for the individual polyesters and the synthesis conditions for optimal performing dispersing agents were indicated as a preference for high molecular weight polyesters and a polyester dependent maximum weight ratio polyester/PEI.
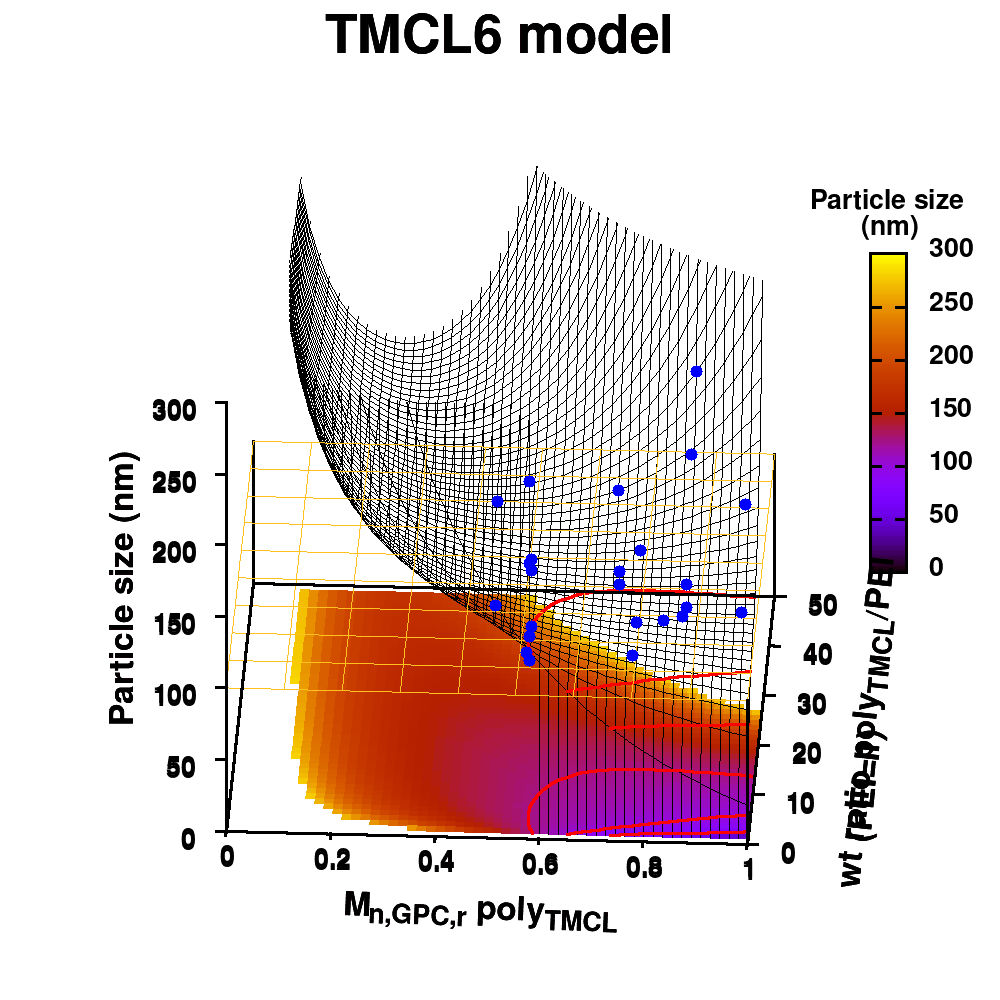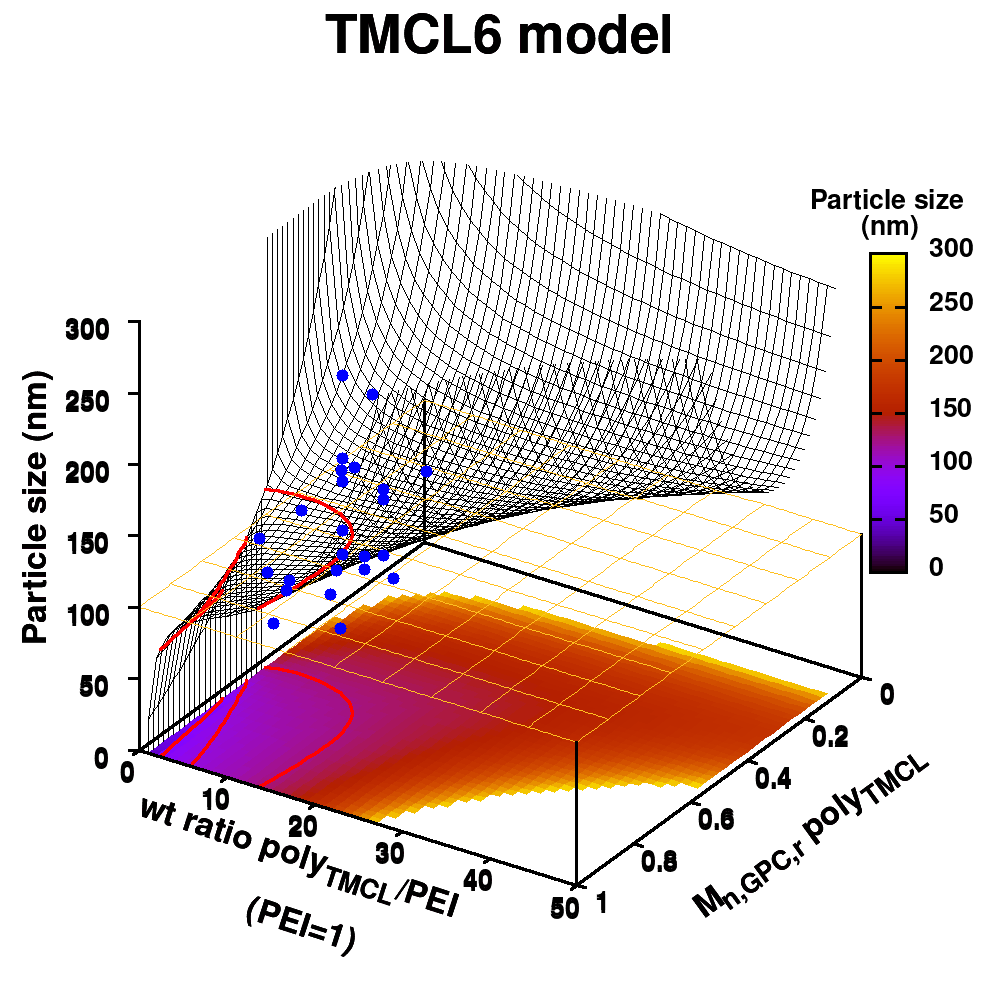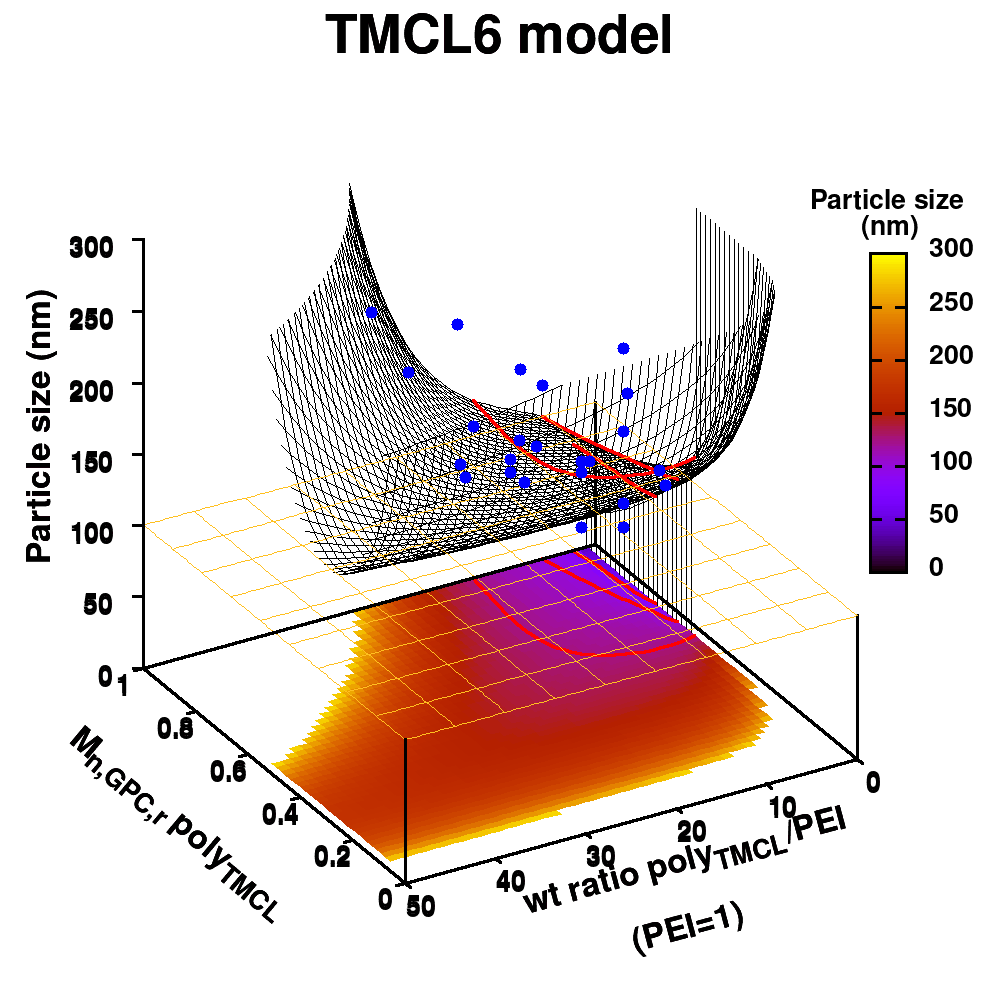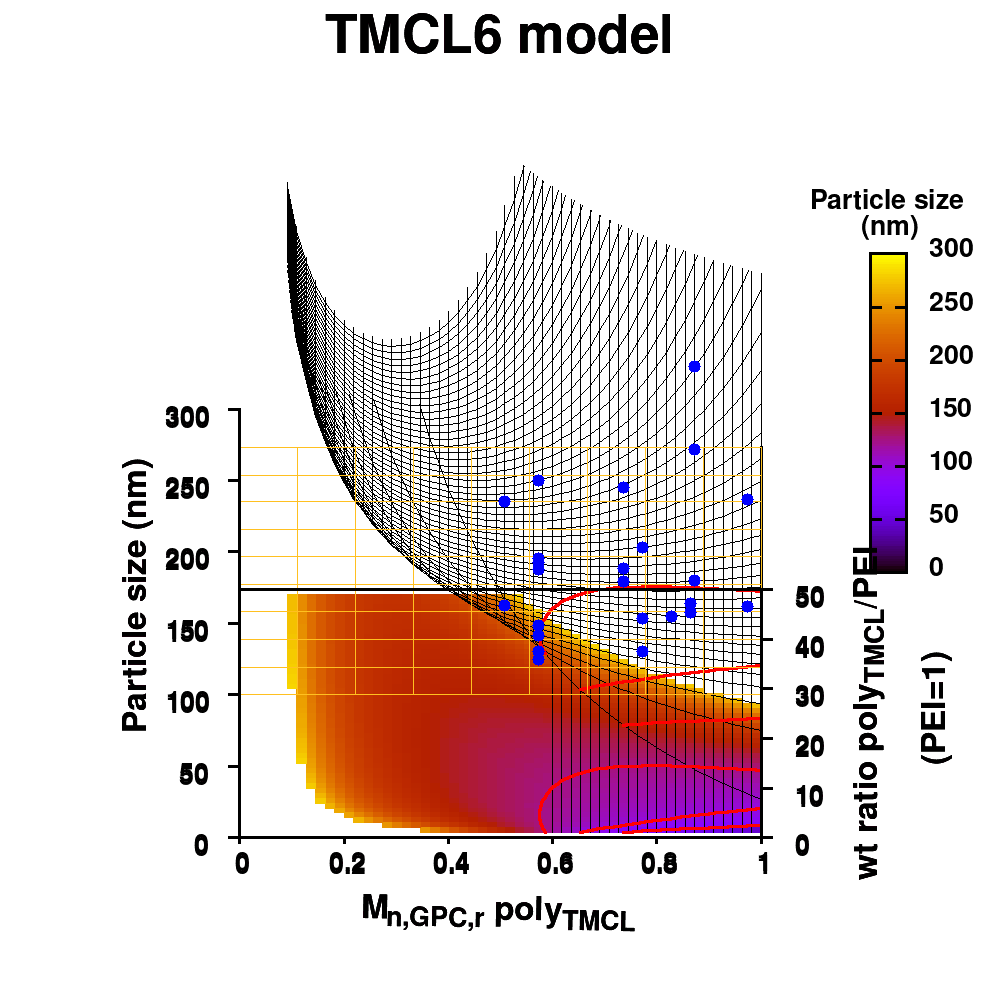
Animation of TMCL model 6
Permanent link to this article: https://dannyvanpoucke.be/paper-ml_inks_um-en/
Apr 21 2022
| Authors: | Kirill N. Boldyrev, Vadim S. Sedov, Danny E.P. Vanpoucke, Victor G. Ralchenko, & Boris N. Mavrin |
| Journal: | Diam. Relat. Mater 126, 109049 (2022) |
| doi: | 10.1016/j.diamond.2022.109049 |
| IF(2020): | 3.315 |
| export: | bibtex |
| pdf: | <DRM> |
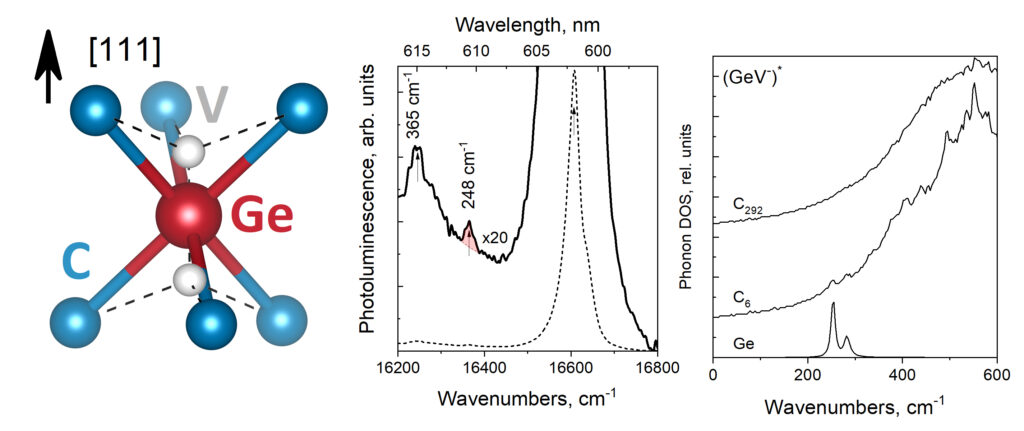 |
| Graphical Abstract: GeV split vacancy defect in diamond and the phonon modes near the ZPL. |
The vibrational behaviour of the germanium-vacancy (GeV) in diamond is studied through its photoluminescence spectrum and first-principles modeled partial phonon density of states. The former is measured in a region below 600 cm−1. The latter is calculated for the GeV center in its neutral, charged, and excited state. The photoluminescence spectrum presents a previously unobserved feature at 248 cm−1 in addition to the well-known peak at 365 cm−1. In our calculations, two localized modes, associated with the GeV center and six nearest carbon atoms (GeC6 cluster) are identified. These correspond to one vibration of the Ge ion along with the [111] orientation of the crystal and one perpendicular to this direction. We propose these modes to be assigned to the two features observed in the photoluminescence spectrum. The dependence of the energies of the localized modes on the GeV-center and their manifestation in experimental optical spectra is discussed.
Permanent link to this article: https://dannyvanpoucke.be/paper_gevpldft_vadim-en/
Mar 10 2022
| Authors: | Sergey Mitryukovskiy, Danny E. P. Vanpoucke, Yue Bai, Théo Hannotte, Mélanie Lavancier, Djamila Hourlier, Goedele Roos and Romain Peretti |
| Journal: | Physical Chemistry Chemical Physics 24, 6107-6125 (2022) |
| doi: | 10.1039/D1CP03261E |
| IF(2020): | 3.676 |
| export: | bibtex |
| pdf: | <PCCP> |
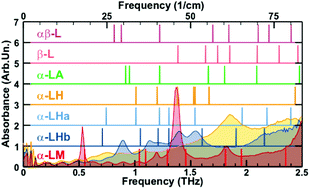 |
| Graphical Abstract: Comparison of the measured THz spectrum of 3 phases of Lactose-Monohydrate to the calculated spectra for several Lactose configurations with varying water content. |
The nanoscale structure of molecular assemblies plays a major role in many (µ)-biological mechanisms. Molecular crystals are one of the most simple of these assemblies and are widely used in a variety of applications from pharmaceuticals and agrochemicals, to nutraceuticals and cosmetics. The collective vibrations in such molecular crystals can be probed using terahertz spectroscopy, providing unique characteristic spectral fingerprints. However, the association of the spectral features to the crystal conformation, crystal phase and its environment is a difficult task. We present a combined computational-experimental study on the incorporation of water in lactose molecular crystals, and show how simulations can be used to associate spectral features in the THz region to crystal conformations and phases. Using periodic DFT simulations of lactose molecular crystals, the role of water in the observed lactose THz spectrum is clarified, presenting both direct and indirect contributions. A specific experimental setup is built to allow the controlled heating and corresponding dehydration of the sample, providing the monitoring of the crystal phase transformation dynamics. Besides the observation that lactose phases and phase transformation appear to be more complex than previously thought – including several crystal forms in a single phase and a non-negligible water content in the so-called anhydrous phase – we draw two main conclusions from this study. Firstly, THz modes are spread over more than one molecule and require periodic computation rather than a gas-phase one. Secondly, hydration water does not only play a perturbative role but also participates in the facilitation of the THz vibrations.
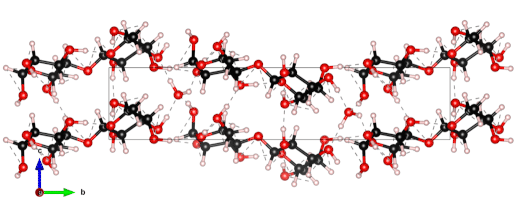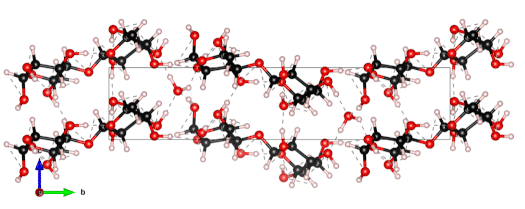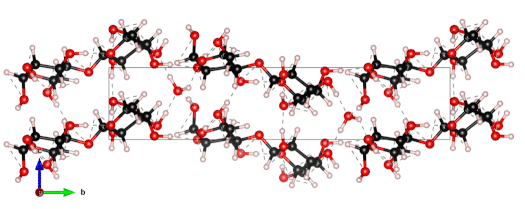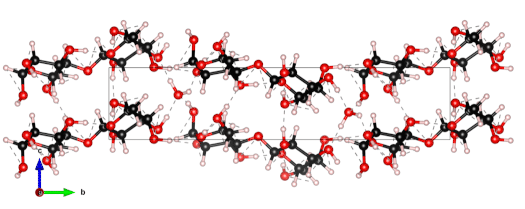
The 0.5 THz finger-print mode of alpha-lactose monohydrate.
Permanent link to this article: https://dannyvanpoucke.be/paper-lactosethz_romain-en/
Feb 27 2022
Python, as any other scripting language allows you to define variables and functions. These are very basic entities when it comes to programming. However, sometimes it is useful to keep variables and functions that are related to one-another close together. This is the main idea behind Object Oriented programming and is present in programming languages such as C++ and fortran, but also in scripting languages like java and python. In this tutorial, you can find a first brief introduction into this topic, focusing on the concept of a class.
This tutorial is part of a series of tutorials and the code is available via GitHub. As a real life example, used throughout this series, we consider a class for solving a wordle-puzzle.
A class is a complex variable type, which contains specific methods (or functions) and attributes (or properties). An instance of such a complex variable is called an object, and different objects can have different values for their attributes (and even methods).
To create a class in python the class keyword is used followed by the name you want to assign your class. In our case this is the WordleAssistant class.
class WordleAssistant():
This WordleAssistant contains the attributes relevant to our puzzle solver. For example, if we want to make a generic solver, two useful attributes would be the wordle word length (WordleSize) and a dictionary of possible words (FullWordset). Unlike fortran or C++, attributes are not defined in the class definition, but can be dynamically created for a class-object. This a feature (or design flaw) gives rise to some dangerous practices such as the runtime (accidental) addition of attributes to an object. For good practices, one should refrain from this and create all attributes by initializing them during the initialization of the class instance. This is done using the __init__() method of the class:
class WordleAssistant(): def __init__(self, size: int = 5, dictionary: str = None): self.WordleSize = size if dictionary is None: dictionary = "Mydict.txt" self.FullWordset = self.readDictionary(dictionary)
Here the WordleSize attribute is defined by setting it to the size parameter of the __init__ method, while the FullWordset attribute is defined by assigning it the result of the readDictionary method of the WordleAssistant class. As is common (and good) practice in OO langues we use the self variable to indicate the instance of the class, binding attributes and methods to the instance. You may also have noted python uses a dot-notation to indicate attributes/methods of a class, similar as C++ (while fortran uses the % symbol with the same effect).
!! NOTE: There also exist “class attributes” which are defined the way one would define instance attributes in fortran or C++. However, in python these attributes are shared by all instances of the class, as such changing them in one object will change them in all objects, creating a mess.
In the previous section, we already defined a first method, the initialization method. As a method is a function, it is constructed as any other function in python using the def keyword, with the body indented. The method itself is indented one level with respect to the class level. Similar as for a usual function, one can indicate the expected type and default value for each function parameter, and if a result is returned the type can be indicated as well, as can be seen in the example below for the readDictionary method.
class WordleAssistant(): def __init__(self, size: int = 5, dictionary: str = None): ... def readDictionary(self, wordlist: str = None)->list: ... return wordlist
Although private attributes and methods don’t technically exist in Python, it is convention that attributes and methods prefixed with a single underscore are to be treated as non-public parts of the API. In addition, using two or more underscores gives rise to name mangling, which gives a practical behavior akin to making attributes and methods private. The __init__ method above is an example. We will come back to this when discussing inheritance and child classes.
Once the class is implemented, it can be used in a script by creating instances of the class. These instances are called Objects.
WA = WordleAssistant()
The above command creates an object WA which is of the class WordleAssistant. The object is initialized through a call to the __init__ method, which is performed by the assignment above. If defaults are provided for all parameters of the __init__ method, then no variables need to be passed to the WordleAssistant class call. Otherwise the creation of an instance could look like this:
wordleSize = 5 WA = WordleAssistant(size=wordleSize,dictionary='MyWords.txt')
Access to the attributes and methods of the WA object s gained using the dot-notation:
wordsize = WA.WordleSize wordlist = WA.FullWordset Top10Guess = WA.getTop(top = 10)
Within the context of data-encapsulation one should never access attributes directly but use get and set methods instead.
Permanent link to this article: https://dannyvanpoucke.be/python-tutorial-classes/
Feb 16 2022
Over that last few months the wordle game has become increasingly popular, with people sharing their daily feats on Twitter. Currently the game is hosted by the NY times which bought it the end of January 2022 from its creator. The game is rather straightforward: you have 6 guesses to find a 5-letter English word. Every guess, the game tells you if a letter is (1) not in the word [grey], (2) in the word at a different position [yellow/orange], or (3) in the word at the exact same position [green].
| Wordle 242 4/6 ⬛⬛🟨⬛⬛ ⬛🟨⬛⬛⬛ ⬛⬛🟩🟨🟩 🟩🟩🟩🟩🟩 |
An example of the result (as it looks when shared on Twitter). My first guess was the word “PIANO”, which means the A is in the word but at a different position. My second word, “QUERY”, adds the U to the list of letters that are present. With my third guess, “STUCK”, the position of the U and the K are fixed and we now also know the letter C is involved. At this point, I was also stuck, so I got some help of my wordle-assistant program, which taught me there could only be 1 word matching all the information we had: “CAULK“. |
This seamlessly brings me to the central topic of this post: writing a program to help win this game as efficiently as possible. Not terribly original, but it’s a means to an end, as this simple project allows us to explore some more advanced topics in programming in python as well as artificial intelligence.
During this exploration I’ll be including and updating a set of tutorials as well as this post. The python side of the project will focus on efficiency and easy of use and distribution, while the AI side will focus on smart ways predicting the best possible next guess. For the latter, an important caveat is that this means that the program should also work if you’re the last player living on earth, or if you decide to play wordle in a different language or a different number of letters. This means that creating a distribution of the tweeted results of other players and comparing this with the complete set of brute-forced distributions to guess the wordle of the day in a single guess, would not satisfy my definition of AI. It is an interesting Big-data kaggle competition though.
All tutorial code and jupyter notebooks can be found in this github repository.
Permanent link to this article: https://dannyvanpoucke.be/wordle-mania-an-opportunity-for-python-programming-and-artificial-intelligence/
Jan 21 2022
| Authors: | Dries De Sloovere, Danny E. P. Vanpoucke, Andreas Paulus, Bjorn Joos, Lavinia Calvi, Thomas Vranken, Gunter Reekmans, Peter Adriaensens, Nicolas Eshraghi, Abdelfattah Mahmoud, Frédéric Boschini, Mohammadhosein Safari, Marlies K. Van Bael, An Hardy |
| Journal: | Advanced Energy and Sustainability Research 3(3), 2100159 (2022) |
| doi: | 10.1002/aesr.202100159 |
| IF(2022): | ?? |
| export: | bibtex |
| pdf: | <AdvEnSusRes> (OA) |
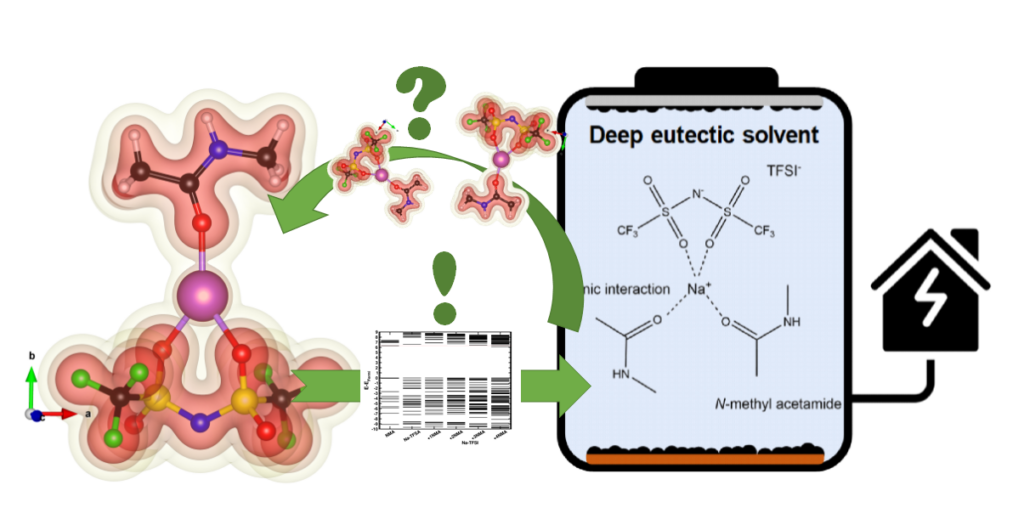 |
| Graphical Abstract: Understanding the electronic structure of Na-TFSI interacting with NMA. |
Sodium-ion batteries are alternatives for lithium-ion batteries in applications where cost-effectiveness is of primary concern, such as stationary energy storage. The stability of sodium-ion batteries is limited by the current generation of electrolytes, particularly at higher temperatures. Therefore, the search for an electrolyte which is stable at these temperatures is of utmost importance. Here, we introduce such an electrolyte using non-flammable deep eutectic solvents, consisting of sodium bis(trifluoromethane)sulfonimide (NaTFSI) dissolved in N-methyl acetamide (NMA). Increasing the NaTFSI concentration replaces NMA-NMA hydrogen bonds with strong ionic interactions between NMA, Na+, and TFSI–. These interactions lower NMA’s HOMO energy level compared to that of TFSI–, leading to an increased anodic stability (up to ~4.65 V vs Na+/Na). (Na3V2(PO4)2F3/CNT)/(Na2+xTi4O9/C) full cells show 74.8% capacity retention after 1000 cycles at 1 C and 55 °C, and 97.0% capacity retention after 250 cycles at 0.2 C and 55 °C. This is considerably higher than for (Na3V2(PO4)2F3/CNT)/(Na2+xTi4O9/C) full cells containing a conventional electrolyte. According to the electrochemical impedance analysis, the improved electrochemical stability is linked to the formation of more robust surface films at the electrode/electrolyte interface. The improved durability and safety highlight that deep eutectic solvents can be viable electrolyte alternatives for sodium-ion batteries.
Permanent link to this article: https://dannyvanpoucke.be/paper-desbatteries_dries-en/
Dec 31 2021
| Authors: | Danny E. P. Vanpoucke and Sylvia Wenmackers |
| Journal: | Chaos 31, 123131 (2021) |
| doi: | 10.1063/5.0063388 |
| IF(2021): | 3.642 |
| export: | bibtex |
| pdf: | <Chaos> (Open Access) <ArXiv v1> |
| github: | <NortonDomeExplorer> |
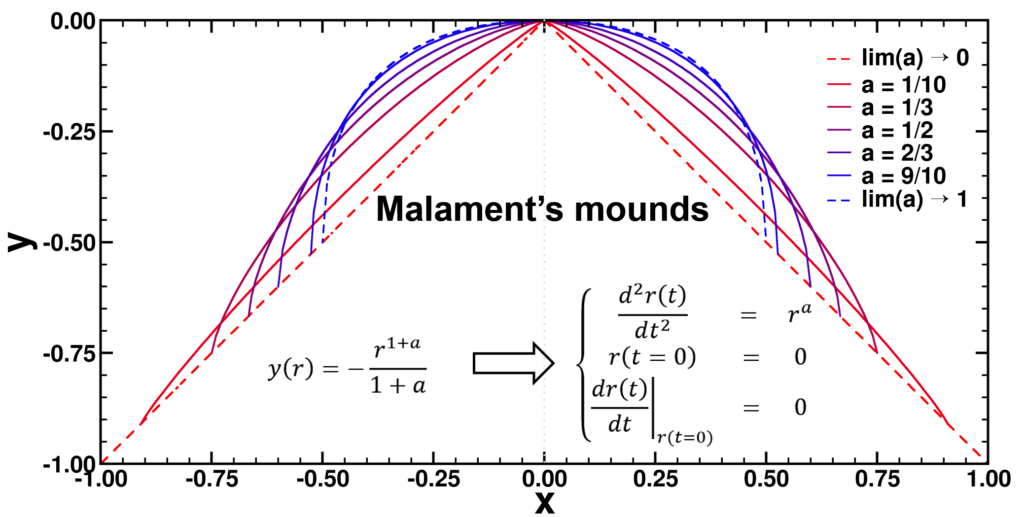 |
| Graphical Abstract: Examples of Malament’s Mounds, of which the Norton Dome is the special case where α=½. |
We present a method for assigning probabilities to the solutions of initial value problems that have a Lipschitz singularity. To illustrate the method, we focus on the following toy-example: 
 = 0")
}= 0")
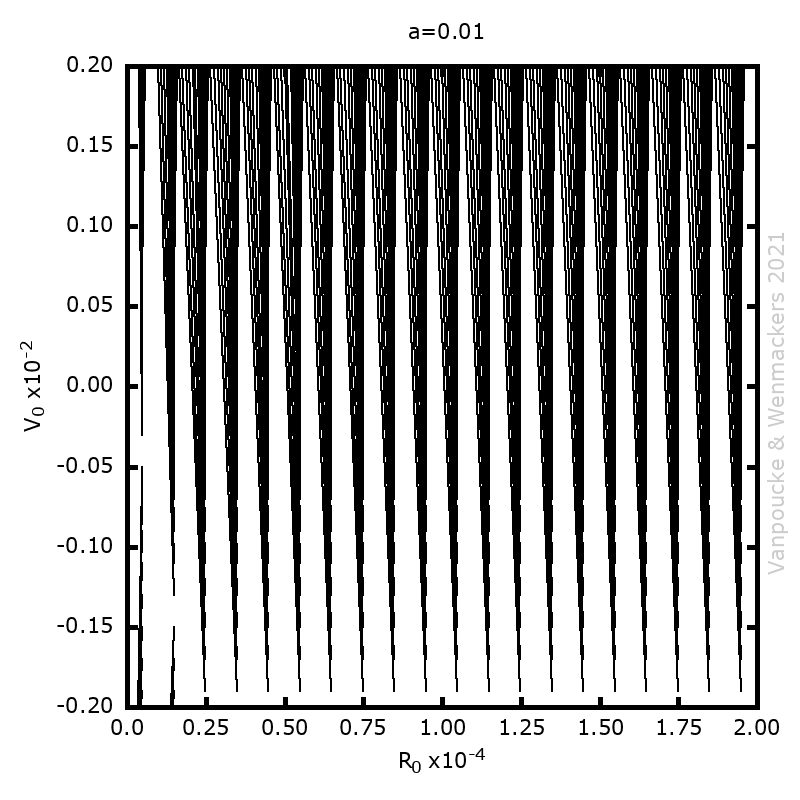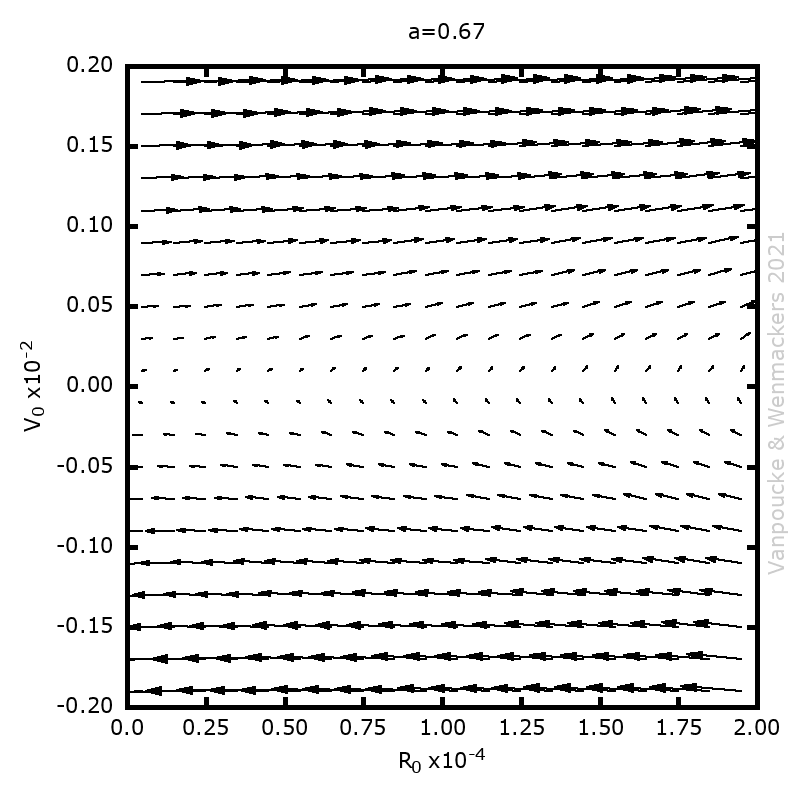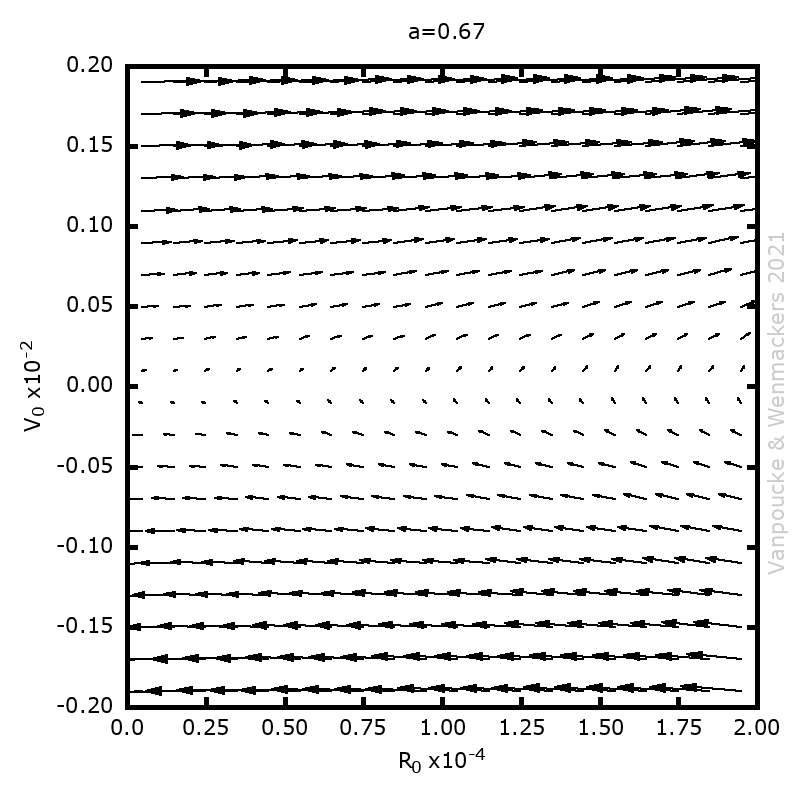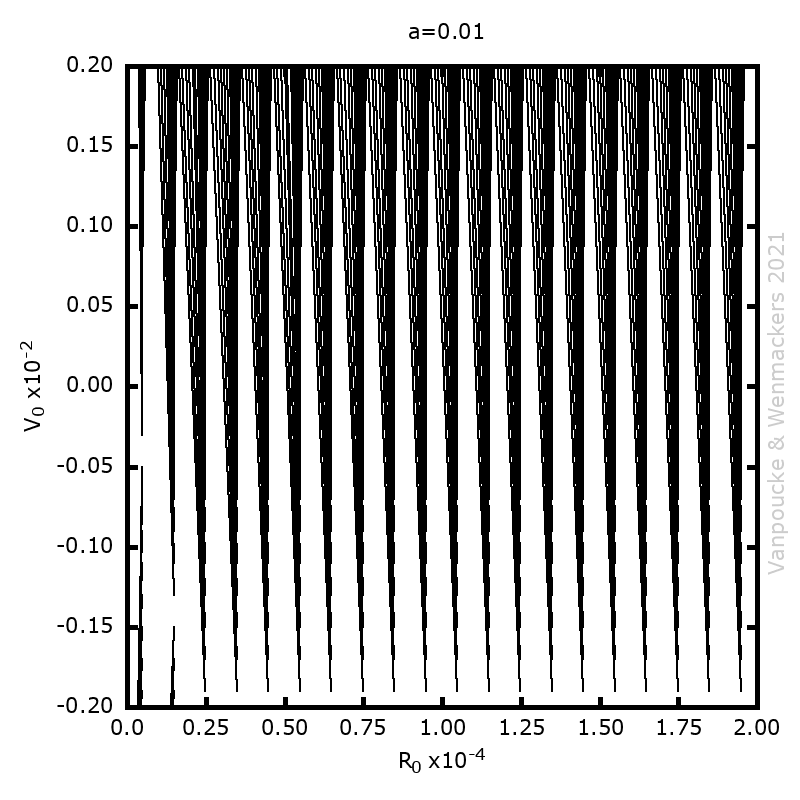
Phase space vector field for all Malament’s mounds
Permanent link to this article: https://dannyvanpoucke.be/paper_domeprogram-en/
May 06 2021
Happy to announce my TEDxUHasselt talk is officially part of the TEDx universe: https://www.ted.com/talks/danny_vanpoucke_the_virtual_lab .
I enjoyed talking about the VirtualLab. Showed examples from atoms to galaxies, from computer-chips to drug-design and from to opinion-dynamics to epidemiology. I looked at the past and and glanced towards the future, where machine learning and artificial intelligence are the new kids on the block.
Permanent link to this article: https://dannyvanpoucke.be/tedx-talk-the-virtual-lab/